2020年4月,Alexey Bochkovskiy在他的Github放出了YOLO检测模型的第四个版本:YOLOv4,比YOLOv3计算量变化不大的前提下,大幅提升了算法效果,在MS COCO数据集上mAP@0.5从33%提升到43.5%。
官方提供训练好的权重文件大小为246MB,提供了80类物体的检测,在PC上通过CPU运行608x608尺寸推理的耗时则达到了2秒多,要在嵌入式环境运行完全无法达到实时性能要求。如果我们只关心某几类物体,能否进行一些优化呢?
我挑选了三类目标:人、猫、狗进行实验。在MS COCO 2017数据集上训练一个可以在VisionSeed(1T FP16算力)上实时运行的YOLOv4-nano模型。
MS COCO 2017包含80类不同的目标框标注,训练集和验证集图片数量如下:
1 2 3 4 5 6 | +-------+--------+--------+------+------+-----+ | | all | person | cat | dog | ... | +-------+--------+--------+------+------+-----+ | train | 118287 | 64115 | 4114 | 4385 | ... | | val | 5000 | 2693 | 184 | 177 | ... | +-------+--------+--------+------+------+-----+ |
可以看到其中包含“人”这一类的图片占到了训练集的一半,因此训练时间估计不会降低太多。
我们再来看看目标硬件平台:VisionSeed,这是一个我在腾讯优图主导推出的,内置了NPU的摄像头模组,售价499,NPU中有专门执行卷积、Maxpool、ReLU的加速单元,因此包含这三类运算比例高的模型能得到最大程度的提速。原版的YOLOv4模型存在NPU不支持的MISH激活函数,把所有激活函数换回硬件支持的ReLU重新训练后,又适配了AnchorInit、候选框生成、NMS等后处理算法,我在VisionSeed上成功跑通了全尺寸的YOLOv4,以512x288的输入分辨率进行推理耗时是464ms,双核跑满能跑到4fps。
进一步优化,我想到了MobileNet提出的一个机制:按比例缩减每一层的channel数量,MobileNet提出了一个alpha值,分别有0.25、0.5、0.75和1.0,例如MobileNet-0.25就是将channel数量缩减到原来的1/4,推理速度提升约4倍,模型大小则降低了16倍!
在此提出YOLOv4-nano系列,相对原版进行了两方面改动:将所有的激活函数换成ReLU以便于NPU加速;对骨干网络的channel数进行按比例缩减。与YOLOv3的tiny系列不同,nano保留了骨干网络的各级残差结构,网络深度不变。并且channel缩减系数比较灵活,对于算力更弱的平台,甚至可以尝试YOLOv4-nano-0.125
经过实验,YOLOv4-nano系列在VisionSeed模组上的单帧耗时如下(512x288)
1 2 3 4 5 6 7 | +--------------+--------+------------------+-----------------+-----------------+ | VisionSeed | YOLOv4 | YOLOv4-nano-0.25 | YOLOv4-nano-0.5 | YOLOv4-nano-1.0 | +--------------+--------+------------------+-----------------+-----------------+ | time | - | 0.114 | 0.211 | 0.464 | | FPS(2-cores) | - | 15 | 8 | 4 | | size(fp16) | 123MB | 7.6MB | 31MB | 123MB | +--------------+--------+------------------+-----------------+-----------------+ |
替换激活函数、缩减channel数量对算法指标有多大影响呢?经过实验,我训练的人猫狗三类目标检测模型所有激活函数替换为ReLU后mAP@0.5从0.83降低到0.82,还算可以接受,最快的YOLOv4-nano-0.25 mAP进一步降低到0.74,相对原版降低9个百分点,但速度有了4倍的提升。YOLOv4-nano系列在MS COCO 2017上只检测人、猫、狗三类的mAP详细指标如下:
1 2 3 4 5 6 7 8 9 | +------------+--------+------------------+-----------------+-----------------+ | mAP@0.5 | YOLOv4 | YOLOv4-nano-0.25 | YOLOv4-nano-0.5 | YOLOv4-nano-1.0 | +------------+--------+------------------+-----------------+-----------------+ | all | 0.83 | 0.74 | 0.78 | 0.82 | +------------+--------+------------------+-----------------+-----------------+ | person | 0.76 | 0.67 | 0.73 | 0.75 | | cat | 0.91 | 0.84 | 0.84 | 0.90 | | dog | 0.81 | 0.70 | 0.75 | 0.80 | +------------+--------+------------------+-----------------+-----------------+ |
训练过程loss和mAP@0.5变化曲线:
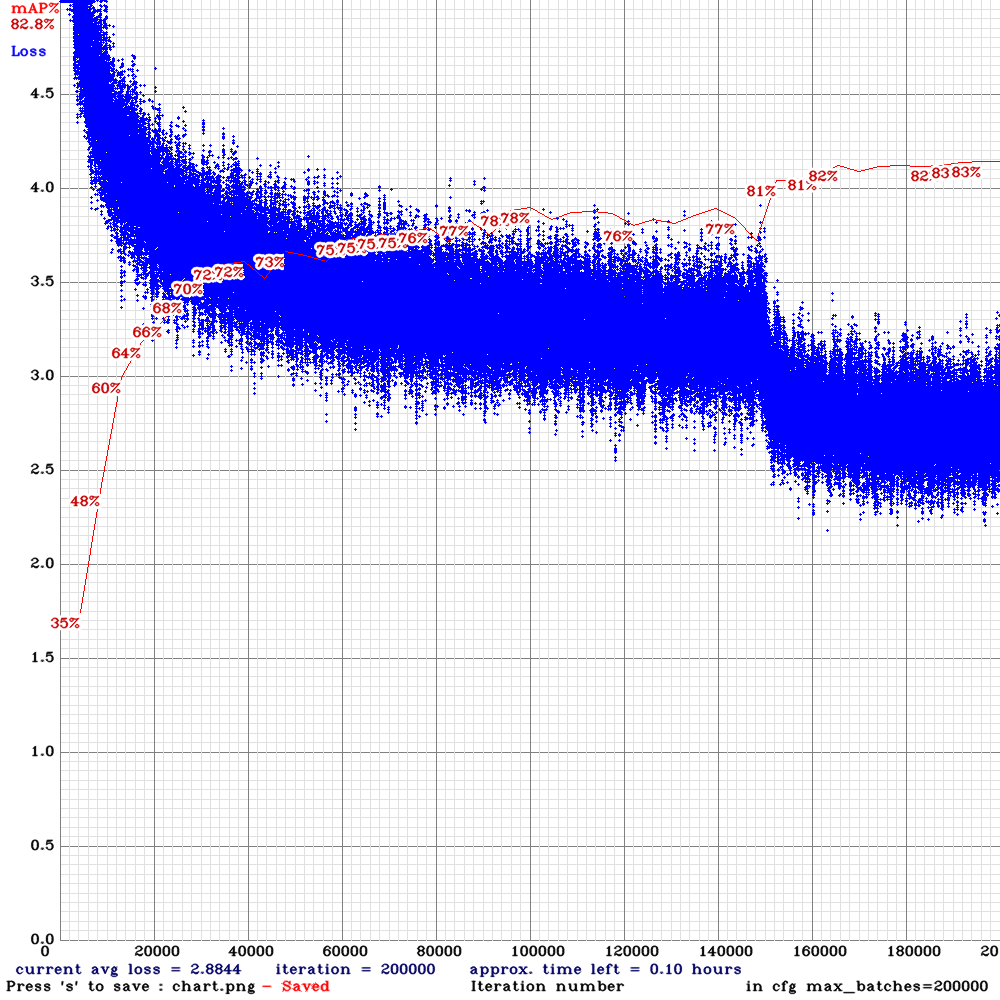
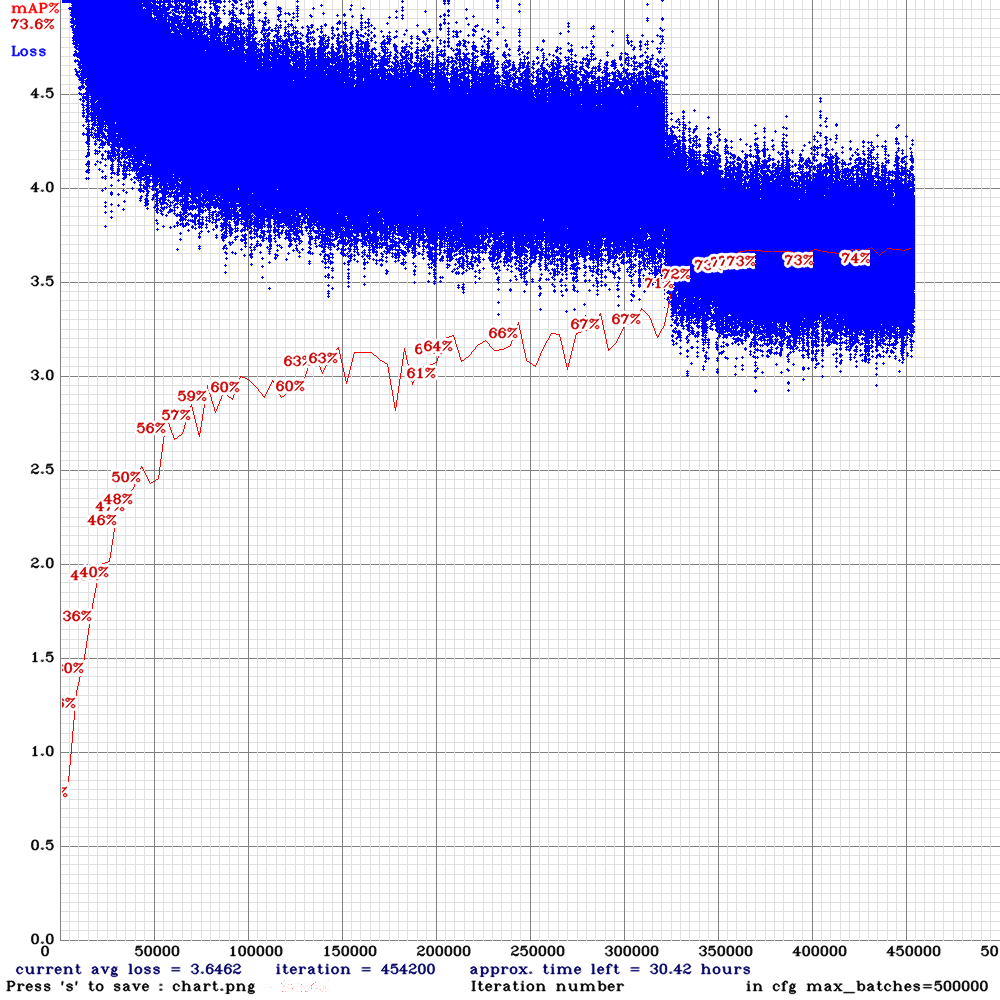
左图:YOLOv4训练曲线 右图:YOLOv4-nano025训练曲线
找一个连续运动视频看看效果:
如果你也想训练自己感兴趣目标的检测器放到这个小模组中运行,那就开始动手吧。在上一篇文章中,配置好了Ubuntu 18.04 CUDA 10.0的编译运行环境,为编译最新的Darknet铺平了道路。
我把本文描述的所有更改,以Makefile/bash脚本的形式开源到https://github.com/liangchen-harold/yolo4-nano.git(欢迎加星),按照如下方式可开箱即用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | # 安装依赖 sudo apt install libopencv-dev # 下载我github上的YOLOv4-nano轻量级脚本,对原版配置文件自动修改 git clone https://github.com/liangchen-harold/yolo4-nano.git cd yolo4-nano make install # 下载MS COCO 2017数据集,解压缩到datasets/coco2017中,文件夹结构如: datasets/ └── coco2017/ ├── annotations/ │ ├── instances_train2017.json │ └── instances_val2017.json └── images/ ├── train2017/ │ ├── 000000000139.jpg │ └── ... └── val2017/ ├── 000000000009.jpg └── ... # 编辑Makefile # 1.选择你需要的类别,替换第5行默认的CLS=cat dog # 2.如果需要尝试不同的大小,调整第13行的NANO=0.25 # 更改过CLS后,一定要运行: make data # 开始训练 make train # 训练完成后,可以输出详细AP信息 make validation # 也可以放一个test.mp4文件后执行 make inference |
如果你有训练好的模型,希望放到VisionSeed中运行,可以留言附上make validation获取的AP信息,获取内测资格哦~