尝试用Inception和MobileNet训练一个二分类模型,折腾了几天,发现MobileNet很难收敛,而Inception训练虽然收敛,但测试时结果却很糟糕。
最后排查下来,只要在测试时把is_training设为True,看起来就正常了,但只要is_training是False,结果就不对。
很容易就排查到了一个问题,从零构建的代码使用如下的方式创建优化器(实际上是错误的):
1 | self.train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(self.loss, global_step=self.global_steps) |
Inception和MobileNet使用的Batch Normalization层需要在训练时统计mini batch的均值和方差并进行滑动更新;在推理时是不进行统计和更新的,而是使用训练时统计好的值。这就要求训练时要进行额外的操作,正确的写法是这样:
1 2 3 | extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) with tf.control_dependencies(extra_update_ops): self.train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(self.loss, global_step=self.global_steps) |
让人意外的是,改正了这个问题后,测试不收敛的问题还是一直萦绕着,虽然多个链接都说按照上面修改后,is_training为False就没问题了[1] [2],但我面临的情况并非如此。
现在的现象仍然是:训练逐渐趋于收敛(accuracy > 0.99),但测试时却是非常奇怪的结果(accuracy 约等于 0.5),而且对任何输入图片,都输出固定的结果,比如[0.503, 0.497]
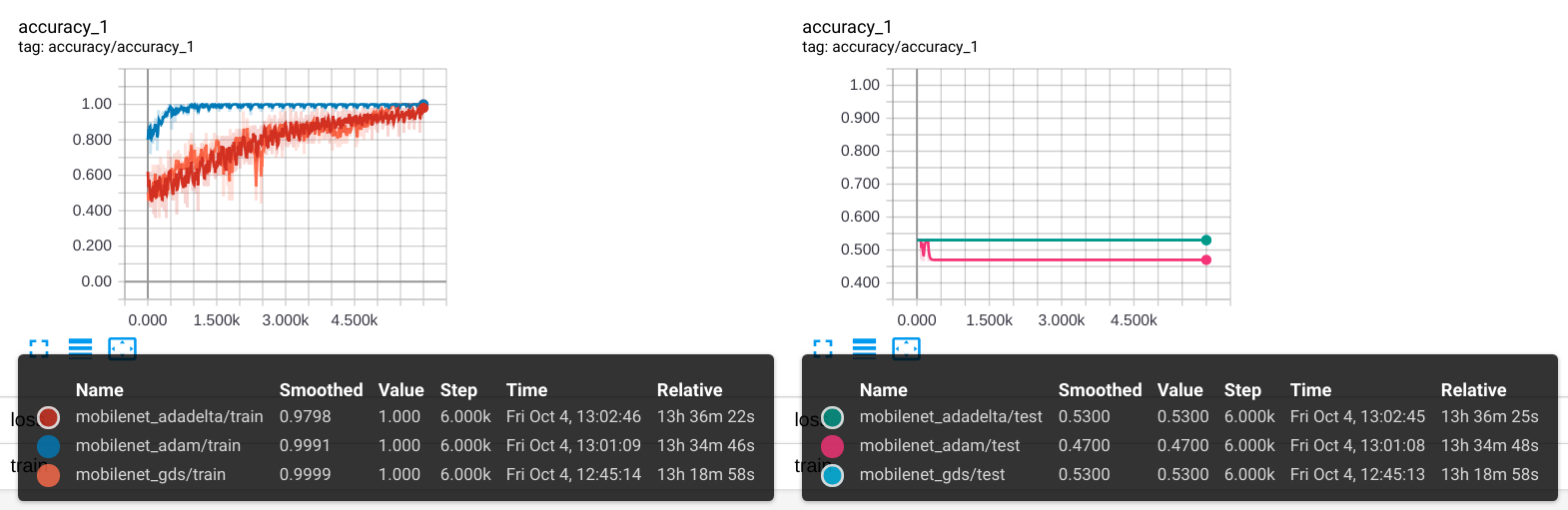
左图:训练收敛 右图:测试不收敛
在slim.mobilenet源码中,is_training只出现了4次,除影响bn层外,还影响了dropout层,通过对照实验很快排除了dropout层,问题锁定在了bn层。bn层有很多参数,其中一个decay参数是控制统计滑动平均的保留率,在mobilenet和inception的实现中,对应于batch_norm_decay,它的默认值为0.9997,逼近速度非常慢,如果我们训练集很小,训练次数也只很少(几千次)的话,均值和方差几乎没有得到更新!奇怪的是,只有很少的文章提到了这个问题[3]
1 2 | with slim.arg_scope(mobilenet_v1.mobilenet_v1_arg_scope(batch_norm_decay=0.95)): self.prediction, ep = mobilenet_v1.mobilenet_v1(xs_reshaped, num_class, dropout_keep_prob=self.keep_prob, is_training=self.is_trainning, depth_multiplier=1) |
将batch_norm_decay设为0.95后,再训练几百次,测试集终于开始有动静了!